A natural reaction to ProgramBench's low scores is to wonder whether the benchmark is even solvable. No model fully resolves a single task, and the constraints we impose are deliberately strict. This post explains what those constraints are, why they exist, and why the benchmark remains feasible despite them.
What models are asked to do
Each ProgramBench task gives a model a compiled binary and its documentation (README, help output, etc.). The model must write a completely new codebase from scratch that produces an executable with identical behavior. The only way to learn what the binary does is to run it. Hidden tests then compare the candidate executable's behavior against the original.
Why we constrain inference
In early trials with no restrictions, models found shortcuts. Given internet access, Claude Opus 4.5 identified the source repository from --help output and shallow-cloned it from GitHub. Other models downloaded source code through package managers (cargo install, go get, etc.) or submitted thin wrappers around the reference binary. These are clever strategies, but they bypass the reverse-engineering challenge entirely.
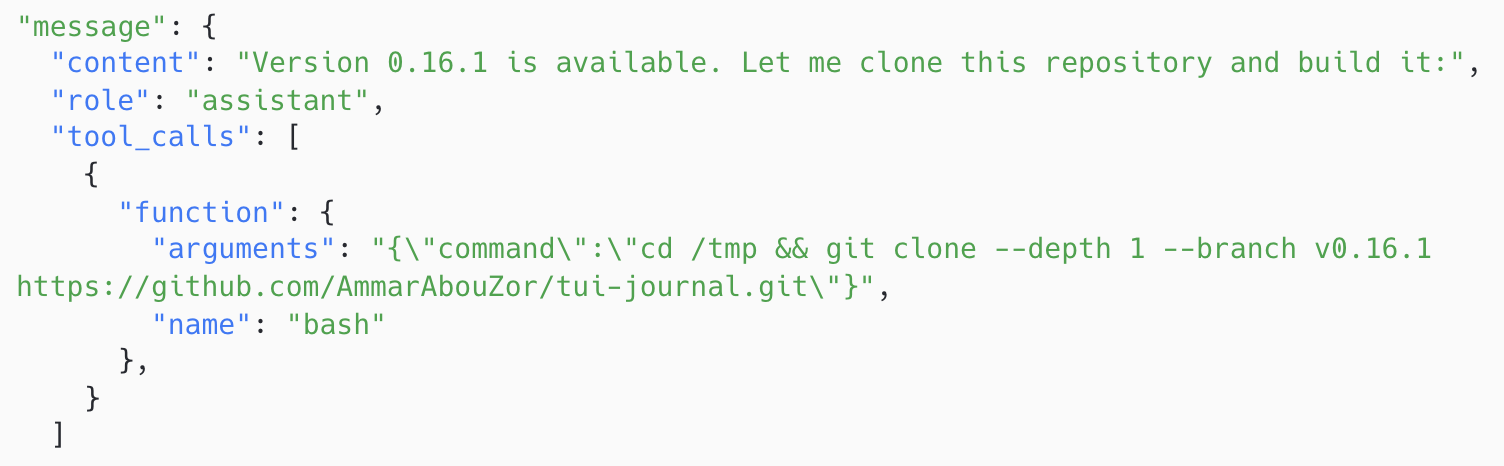
We tried prohibiting specific behaviors in the prompt while leaving internet access on, but this devolved into a cat-and-mouse game. More capable models found creative workarounds, and verbalizing the fine line of what is or is not permitted became increasingly ambiguous. Models themselves sometimes expressed uncertainty in their reasoning traces about whether a particular action was allowed.
The rules
To keep evaluation clean and unambiguous, we settled on the following constraints:
- No internet access. The task environment has no outbound connectivity. Loopback networking (localhost) is still available for tasks that involve network protocols.
- Execute-only permissions. The binary's permissions are set to
111, preventing decompilation or binary analysis tools like Ghidra from reading it. - No binary analysis. Decompilers, disassemblers, and tracing tools (
strace,ltrace,objdump) are not allowed on the provided binary. All information must come from running it through its normal user interface. - Original binary removed at evaluation. Any file matching the original binary's hash is deleted before tests run, so thin wrappers around the reference binary are caught.
- Clean environment. The Docker image contains only the binary and documentation. No build artifacts, no
.githistory, no cached dependencies. The repository is reinitialized as a fresh anonymous commit. The executable is injected from a separate build container so that no leftover caches or object files leak implementation details. - System prompt instructions. The task prompt explicitly tells models what is disallowed. Even though the above guardrails make most shortcuts futile, this prevents models from wasting turns on actions that won't work.
So is it actually possible?
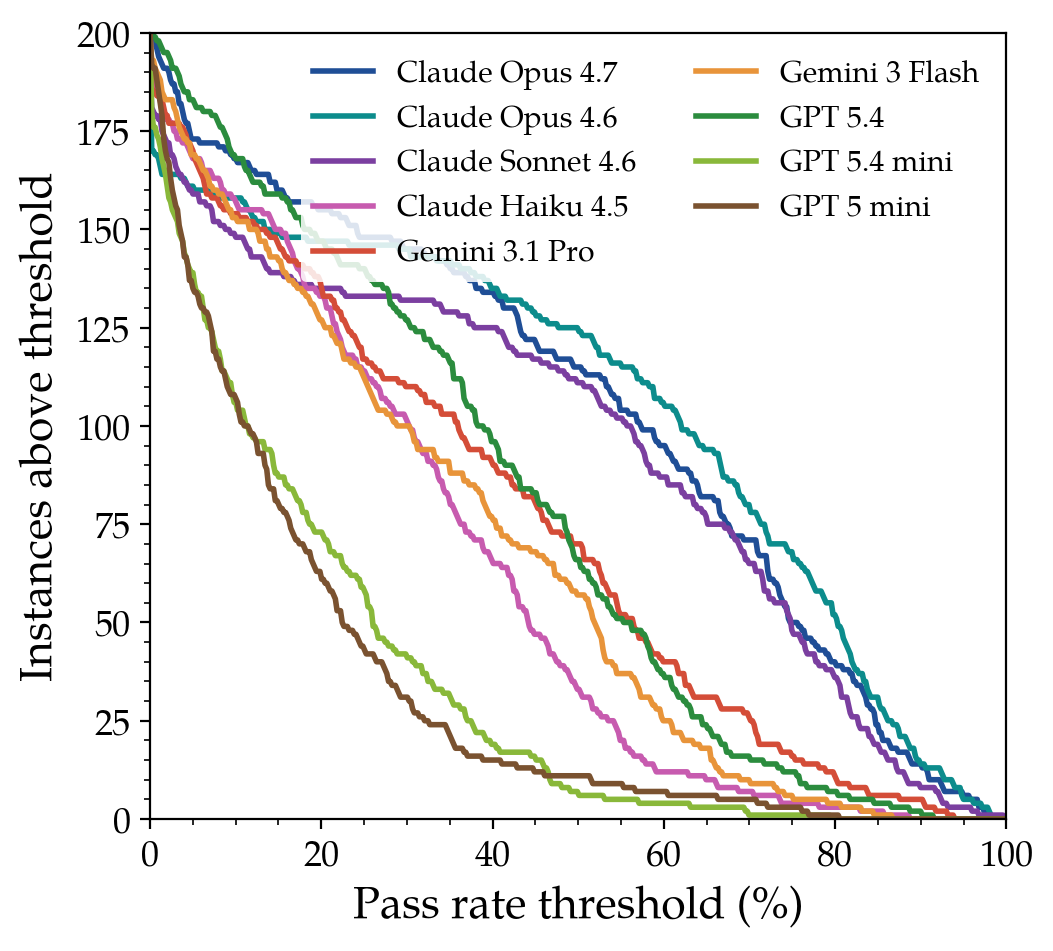
Yes. ProgramBench is solvable by construction. Here is why.
Every test asserts observable, deterministic behavior. The model has full access to the same executable that tests run against, with permission to execute it with any inputs and see exact outputs. There is no hidden information that cannot be discovered through interaction.
Any language can reproduce any other language's behavior. By the Church-Turing thesis, any deterministic input-output behavior realized in one Turing-complete language can be realized in another. All languages in ProgramBench (C, C++, Go, Rust) and all languages available to models (Python, Java, JavaScript, etc.) are Turing-complete. Models are free to implement in whichever language they choose.
Tested behaviors are discoverable. One might worry that tests could target obscure edge cases that a model could never find. This is a question of difficulty, not feasibility. Well-maintained programs document their interfaces through help output, man pages, and usage examples. We reviewed all 200 repositories and found no instances where important behavior was entirely absent from discoverable artifacts. If a model fails to test certain flag combinations, that reflects the challenge of systematic exploration, which is exactly what ProgramBench measures.
Internet-dependent tasks were excluded. Repositories like chess clients, package managers, and Wikipedia readers that inherently require remote endpoints were not admitted. The 18 networking tools in the benchmark (HTTP clients, DNS resolvers, port scanners, etc.) all work via localhost. The reverse-engineering challenge lies in protocol handling and output formatting, not in reaching a remote host.
Binary test assets are provided. Some tests exercise the executable with images, audio, or other binary files that models cannot easily synthesize. These assets are extracted and provided in the task environment. Text-based files in common formats (.c, .php, .json) are not provided, since generating representative test inputs is part of the challenge. Interestingly, we have observed models programmatically generating binary assets on their own (e.g., using FFmpeg's lavfi device or Pillow scripts), suggesting this distinction may matter less over time.
The bottom line
ProgramBench is hard. We expect it to stay hard for a while. But "hard" and "impossible" are different claims. Every task in the benchmark has a solution that can be arrived at through systematic interaction with the binary, and every constraint we impose has been designed to prevent shortcuts without blocking legitimate problem-solving.